TP partie 4 - Introduction aux VPC avec un exemple simple
Dans cette quatrième partie, nous allons découvrir les concepts fondamentaux des VPC (Virtual Private Cloud) AWS en créant une architecture réseau simple. Nous reprendrons notre serveur web de la partie 3 mais cette fois-ci dans un VPC personnalisé.
Qu’est-ce qu’un VPC AWS ?
Section titled “Qu’est-ce qu’un VPC AWS ?”Un VPC (Virtual Private Cloud) est un réseau virtuel dédié à votre compte AWS. C’est un environnement isolé logiquement du reste du cloud AWS où vous pouvez lancer vos ressources dans un réseau virtuel que vous définissez. Contrairement aux parties précédentes où nous utilisions le VPC par défaut d’AWS, nous allons maintenant créer et configurer notre propre VPC.
Avantages d’un VPC personnalisé
Section titled “Avantages d’un VPC personnalisé”Créer son propre VPC offre plusieurs avantages par rapport à l’utilisation du VPC par défaut. Vous avez un contrôle total sur l’architecture réseau, vous pouvez définir vos propres plages d’adresses IP et configurer les tables de routage selon vos besoins. Cela permet également une meilleure sécurité grâce à l’isolation réseau et la possibilité de créer des environnements multi-tiers.
Architecture de notre VPC simple
Section titled “Architecture de notre VPC simple”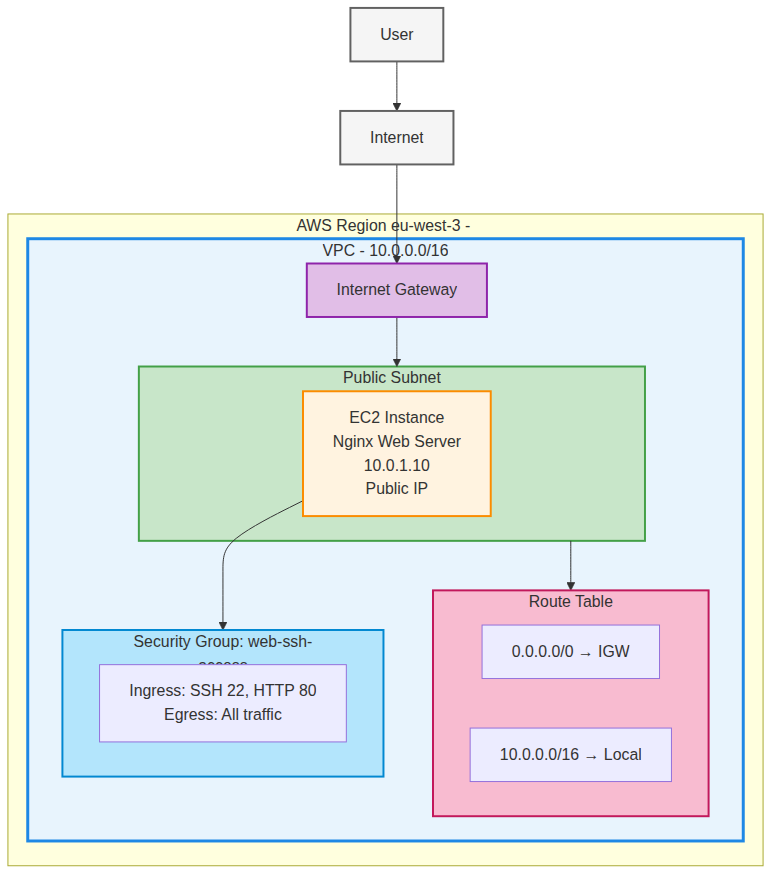
Notre architecture comprend les éléments essentiels d’un VPC fonctionnel. Nous créons un VPC avec un seul subnet public contenant notre serveur web Nginx, une Internet Gateway pour l’accès Internet, une table de routage pour diriger le trafic et un Security Group pour contrôler l’accès.
Construction progressive du VPC
Section titled “Construction progressive du VPC”Nous allons construire notre infrastructure bloc par bloc pour bien comprendre chaque composant et son rôle dans l’architecture réseau.
Étape 1 : Création du VPC de base
Section titled “Étape 1 : Création du VPC de base”Partez du code de la partie 3 (copiez le dossier part3 vers part4 ou commitez les changements de part3 et créez une nouvelle branche).
Important : Dans cette partie, nous abandonnons l’approche AMI personnalisée + remote-exec de la partie 2 pour adopter une approche plus moderne avec user-data. Cela simplifie le déploiement et améliore la scalabilité.
Ajoutez le bloc VPC au début de votre fichier main.tf :
# VPCresource "aws_vpc" "main" { cidr_block = "10.0.0.0/16" enable_dns_hostnames = true enable_dns_support = true
tags = { Name = "main-vpc" }}Le bloc VPC définit notre réseau virtuel privé avec une plage d’adresses IP de 10.0.0.0/16, ce qui nous donne 65 536 adresses IP disponibles. Les paramètres enable_dns_hostnames et enable_dns_support activent la résolution DNS dans le VPC, permettant aux instances d’avoir des noms DNS.
Internet Gateway
Section titled “Internet Gateway”Ajoutez l’Internet Gateway pour permettre l’accès Internet :
# Internet Gatewayresource "aws_internet_gateway" "main" { vpc_id = aws_vpc.main.id
tags = { Name = "main-igw" }}L’Internet Gateway (IGW) est le composant qui permet aux ressources du VPC de communiquer avec Internet. Elle est attachée au VPC via vpc_id et constitue le point d’entrée et de sortie pour tout le trafic Internet.
Subnet public
Section titled “Subnet public”Créez maintenant un subnet public pour héberger notre serveur web :
# Subnet publicresource "aws_subnet" "public" { vpc_id = aws_vpc.main.id cidr_block = "10.0.1.0/24" map_public_ip_on_launch = true
tags = { Name = "public-subnet" }}Le subnet utilise une partie de la plage IP du VPC (10.0.1.0/24 = 256 adresses). Le paramètre map_public_ip_on_launch fait que les instances lancées dans ce subnet reçoivent automatiquement une adresse IP publique.
Table de routage
Section titled “Table de routage”Ajoutez la table de routage qui définit comment le trafic est acheminé/routé :
# Route tableresource "aws_route_table" "public" { vpc_id = aws_vpc.main.id
route { cidr_block = "0.0.0.0/0" gateway_id = aws_internet_gateway.main.id }
tags = { Name = "public-route-table" }}Cette table de routage contient une route par défaut (0.0.0.0/0) qui dirige tout le trafic Internet vers l’Internet Gateway. AWS ajoute automatiquement une route locale pour le trafic interne au VPC.
Association subnet-route table
Section titled “Association subnet-route table”Associez le subnet à la table de routage :
# Association subnet avec route tableresource "aws_route_table_association" "public" { subnet_id = aws_subnet.public.id route_table_id = aws_route_table.public.id}Cette association indique que le trafic du subnet public doit utiliser la table de routage publique pour déterminer sa destination.
Modification du Security Group
Section titled “Modification du Security Group”Le Security Group de la partie 3 doit être légèrement modifié pour fonctionner dans notre VPC personnalisé. Modifiez le bloc Security Group existant en ajoutant simplement le paramètre vpc_id :
# Security Group - modification de la partie 3resource "aws_security_group" "web_ssh_access" { name = "web-ssh-access-<votre-prenom>" description = "Allow SSH and HTTP access" vpc_id = aws_vpc.main.id # <-- Ligne ajoutée pour le VPC personnalisé
# Le reste reste identique à la partie 3 ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] }
ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] }
egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] }
tags = { Name = "Web and SSH Access" }}La seule différence avec la partie 3 est l’ajout de vpc_id = aws_vpc.main.id qui indique que ce Security Group appartient à notre VPC personnalisé et non au VPC par défaut d’AWS.
Configuration de l’AMI Ubuntu et user-data
Section titled “Configuration de l’AMI Ubuntu et user-data”Au lieu d’utiliser l’AMI personnalisée de la partie 2, nous allons maintenant utiliser l’AMI Ubuntu standard et configurer l’instance via user-data. Ajoutez d’abord les data sources :
# Data source pour l'AMI Ubuntu standarddata "aws_ami" "ubuntu" { most_recent = true owners = ["099720109477"] # Canonical
filter { name = "name" values = ["ubuntu/images/hvm-ssd/ubuntu-jammy-22.04-amd64-server-*"] }
filter { name = "virtualization-type" values = ["hvm"] }}
# Template pour user-datadata "template_file" "user_data" { template = <<-EOF#!/bin/bash
# Mettre à jour le systèmeapt-get update
# Créer l'utilisateur et configurer SSHif ! id "terraform" &>/dev/null; then useradd -m -s /bin/bash terraform usermod -aG sudo terraform echo 'terraform ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoersfi
# Créer le répertoire .sshmkdir -p /home/terraform/.sshchmod 700 /home/terraform/.ssh
# Ajouter la clé publique SSH (remplacez par votre clé publique)echo "${ssh_public_key}" > /home/terraform/.ssh/authorized_keyschmod 600 /home/terraform/.ssh/authorized_keyschown -R terraform:terraform /home/terraform/.ssh
# Installer et configurer nginxapt-get install -y nginxsystemctl start nginxsystemctl enable nginx
# Créer la page d'accueilecho '<h1>Hello from VPC!</h1>' > /var/www/html/index.htmlecho '<p>Serveur configuré avec user-data</p>' >> /var/www/html/index.html
echo "Configuration terminée avec user-data"EOF
vars = { ssh_public_key = file("~/.ssh/id_terraform.pub") }}Pourquoi user-data plutôt que remote-exec ?
Le script user-data s’exécute automatiquement au premier démarrage de l’instance, avant même que Terraform essaie de s’y connecter. Cette approche :
- Élimine les dépendances : Pas besoin d’AMI personnalisée ou de connexion SSH pendant le provisioning
- Améliore la fiabilité : Le script s’exécute indépendamment de Terraform
- Simplifie la gestion : Une seule source de vérité pour la configuration initiale
- Permet le scaling : Plus facile à intégrer avec des Auto Scaling Groups
Instance EC2 avec user-data
Section titled “Instance EC2 avec user-data”Maintenant, créez l’instance EC2 en utilisant l’AMI Ubuntu standard et le script user-data :
# Instance EC2 avec user-dataresource "aws_instance" "web_server" { ami = data.aws_ami.ubuntu.id instance_type = "t2.micro" subnet_id = aws_subnet.public.id vpc_security_group_ids = [aws_security_group.web_ssh_access.id] user_data = data.template_file.user_data.rendered
tags = { Name = "nginx-web-server-vpc" }}Changements importants :
- AMI :
data.aws_ami.ubuntu.idau lieu de l’AMI personnalisée - user_data : Le script de configuration s’exécute automatiquement
- Pas de provisioner : Plus besoin de
connectionetremote-exec - Utilisateur : Le script crée un utilisateur
terraformavec votre clé SSH
Outputs
Section titled “Outputs”Ajoutez les outputs pour afficher les informations importantes :
# Outputsoutput "vpc_id" { value = aws_vpc.main.id}
output "subnet_id" { value = aws_subnet.public.id}
output "instance_id" { value = aws_instance.web_server.id}
output "instance_public_ip" { value = aws_instance.web_server.public_ip}
output "web_url" { value = "http://${aws_instance.web_server.public_ip}"}Ces outputs vous permettent de voir les IDs des ressources créées et l’URL pour accéder au serveur web.
Différences avec le VPC par défaut
Section titled “Différences avec le VPC par défaut”Notre VPC personnalisé diffère du VPC par défaut sur plusieurs points importants. Nous contrôlons entièrement la configuration réseau, nous définissons nos propres plages IP et nous créons explicitement tous les composants (IGW, subnets, route tables). Cela nous donne une meilleure visibilité et un contrôle total sur l’architecture.
Déploiement et vérification
Section titled “Déploiement et vérification”Déployez l’infrastructure en utilisant une approche plus sécurisée avec le paramètre -out :
terraform initterraform plan -out=tfplanPourquoi utiliser -out avec terraform plan ?
Le paramètre -out de terraform plan est une bonne pratique importante pour plusieurs raisons :
Sécurité et cohérence : Il garantit que les modifications appliquées avec terraform apply correspondent exactement à ce qui a été planifié et validé. Sans ce paramètre, il pourrait y avoir des différences entre ce que vous avez vu dans le plan et ce qui est réellement appliqué si des changements ont eu lieu entre les deux commandes.
Environnements de production : Dans un environnement de production ou dans un pipeline CI/CD, cette approche est essentielle. Elle permet de valider le plan dans une étape séparée (review, approbation) avant l’application effective des changements.
Audit et traçabilité : Le fichier de plan peut être conservé comme trace de ce qui a été appliqué à un moment donné, facilitant les audits et le debugging.
Maintenant nous pouvons réafficher le plan avec terraform show tfplan
- Etudiez le diff :
Plan: 7 to add, 0 to change, 2 to destroy.
Est-ce que notre mise à jour implique de la haute disponibilité ? Pourquoi ?
La resource aws_instance i.e. notre serveur doit être remplacé par AWS pour pouvoir être connecté au nouveau subnet. Terraform implique de façon générale une vision immutable des serveurs (ils sont jetés et recréés comme des conteneurs). Pour éviter un coupure de service il va nous falloir une architecture HA permettant le remplacement progressif de plusieurs instances.
Appliquez enfin les modification avec la commande :
terraform apply tfplanUne fois le déploiement terminé, vous pouvez accéder au serveur web via l’URL affichée dans les outputs. La page affichera “Hello from VPC!” confirmant que le serveur fonctionne dans votre VPC personnalisé.
Connexion SSH : Pour vous connecter au serveur, utilisez maintenant l’utilisateur terraform créé par le script user-data :
ssh -i ~/.ssh/id_terraform terraform@<IP_PUBLIQUE>Le script user-data prend quelques minutes pour s’exécuter complètement. Vous pouvez vérifier son exécution via les logs système une fois connecté :
sudo tail -f /var/log/cloud-init-output.log